
AEO: Getting Started
Prefer to listen?
Last year I began hearing people talk about AEO, Answer Engine Optimization, and how important it is to get AI to recommend your product or services as people are going to AI for answers for more of the questions they used to type into Google Search. I went to AI anonymously and tried to get it to recommend my product to me when I asked it specific questions that my product provides answers for. I wasn't too surprised when it didn't know anything about my product or what it did or what problems it solved, but I was honestly pretty discouraged.
I felt like it was impossible for a small business to ever get recommended on AI platforms when the behemoth companies already own SEO success and have full-time, dedicated staff working on AEO solutions. I felt overwhelmed. -me
Then I listened to Ethan Smith's AEO playbook on Lenny's Podcast, and hope was sparked. I took what I learned and built a game plan from there, one that even exceeded his playbook. I'm going to walk you through my ongoing practice of AEO and what changes I've seen over the last six months.
I'll show you what we changed on hedge-ops.com and people-work.io, the types of prompts I used to make the changes, and where AEO continues to show me where I have a lack of clarity in my business messaging, giving me opportunities for improvement.
Intro to AEO - What is AEO and why does it matter?
AEO = SEO + citation optimizationYou can think of AEO as SEO for AI, but, more specifically, it's SEO plus citation optimization. SEO will rank your relevance, but AEO will determine whether or not AI should cite you as a resource for a particular topic.
AEO is not a one and done exercise but an ongoing practice. I will show you certain things that you can put in place and forget about it, but at the heart of AEO is building trust and credibility, which takes time and consistency.
The four levers small businesses can pull for good AEO
- Structured data - the hidden labels AI reads
- Semantic HTML - making pages that AI can extract and quote
- llms.txt - publishing for AI directly
- Off-site presence - building credibility out in the wild
Lever 1: Structured data (the hidden labels AI reads)
If you're not technical and don't know what this is, fear not. It's not as complicated as it sounds. Let me show you.
What structured data is, in plain English
Our websites have two different views. There's one that we can see and one that the machines can see. What we can see is a very decorated and lovely view designed for human eyes.
What the machines can see is basically all of the metadata that a machine needs to make a determination on your website.
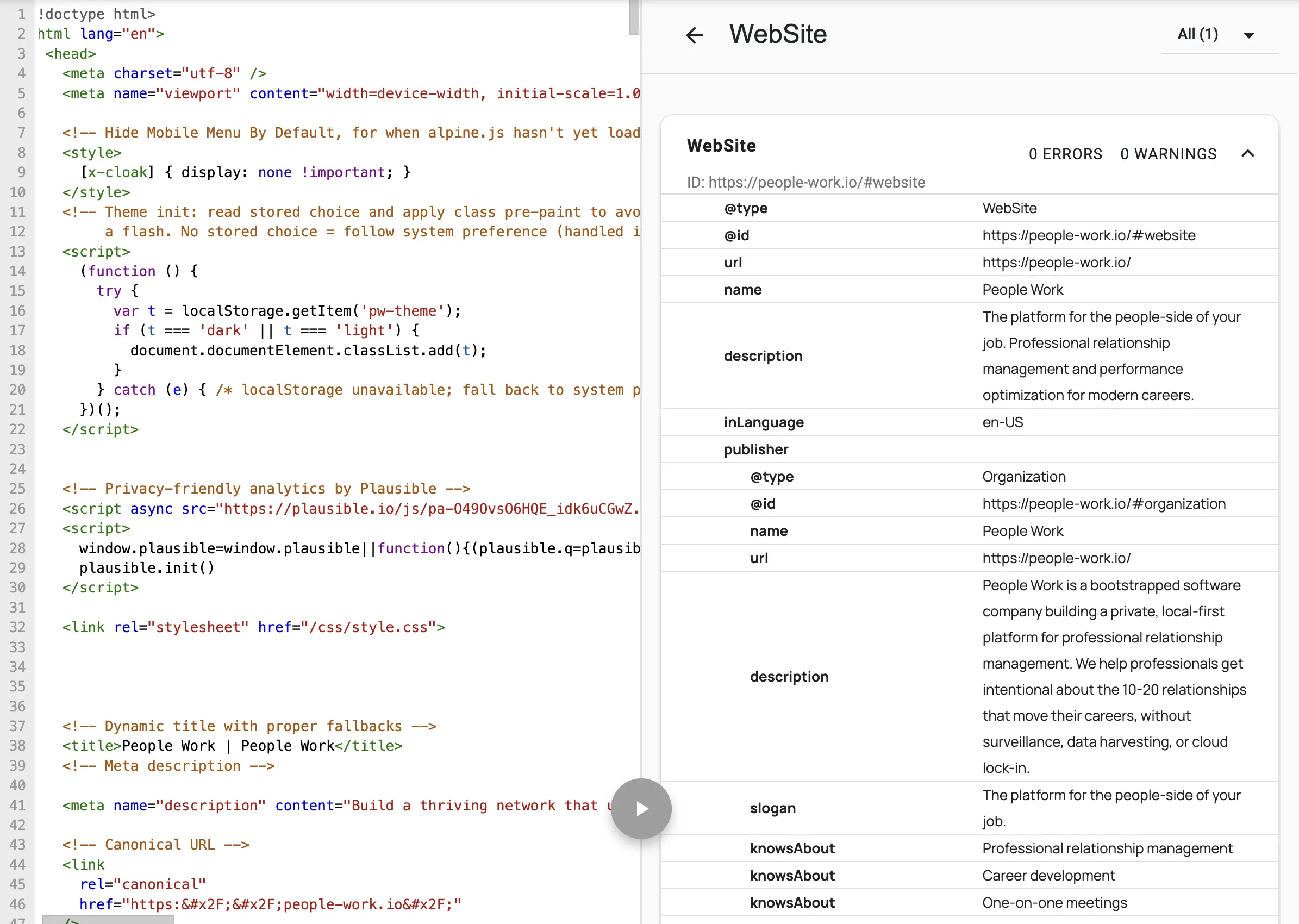
There is JSON code embedded in every page that gives AI the stripped down version of what it needs to know. On the left you can see the JSON code, and on the right you can see a more human-readable version of the same thing.
To see this for your own website, go to https://validator.schema.org/ and enter in your URL. Before I worked on my AEO, this view was abysmal. It was missing data, had outdated descriptions, and overall lacking.
The @graph pattern (and why a single block beats multiple)
There are two ways you can hand over this data from above to an AI: as separate index cards or one connected map. Most sites do it the first way:
<script type="application/ld+json">
{ "@type": "Organization", "name": "Hedge-Ops Software" }
</script><script type="application/ld+json">
{ "@type": "WebPage", "name": "Our services" }
</script><script type="application/ld+json">
{ "@type": "Article", "headline": "Why people work matters" }
</script>These blocks don't reference each other, so AI has to guess if and how they're related.
On the other hand, if an AI lands on this very blog post that you're reading, it will know that:
- It was written by Annie Hedgpeth.
- She is the co-founder of Hedge-Ops Software.
- They created People Work.
- There's more on LinkedIn and all of these other references on the connected map.
It's able to verify my credibility this way because it "asked around", just like you would if you were verifying a person's credibility.
We collapse everything into one block with one @graph array simply so that it's easier to reason about the site. Every page on my sites emits exactly one <script type="application/ld+json"> block in <head> containing a single @graph array. Every entity gets a unique label (or @id), and then entities point at each other using those labels.
| Entity | @id |
|---|---|
| Your company | https://yoursite.com/#organization |
| Your website itself | https://yoursite.com/#website |
| A founder or person | https://yoursite.com/#person-jane-doe |
| A specific page | https://yoursite.com/some-page/#webpage |
| A blog post | https://yoursite.com/posts/the-slug/#blogposting |
| A service offering | https://yoursite.com/#consulting |
Your AI or your developer will generate this template (but with your info) just once, and then every page renders its own. (See the prompts below.)
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Organization",
"@id": "https://hedge-ops.com/#organization",
"name": "Hedge-Ops Software",
"sameAs": [
"https://www.linkedin.com/company/hedge-ops-software-llc",
"https://www.youtube.com/@People-Work",
"https://x.com/peopleworkio"
]
},
{
"@type": "Person",
"@id": "https://hedge-ops.com/#person-annie-hedgpeth",
"name": "Annie Hedgpeth",
"sameAs": [
"https://www.linkedin.com/in/annie-hedgpeth",
"https://x.com/anniehedgie",
"https://github.com/anniehedgpeth"
]
},
{
"@type": "BlogPosting",
"@id": "https://hedge-ops.com/posts/this-post/#blogposting",
"author": { "@id": "https://hedge-ops.com/#person-annie-hedgpeth" },
"publisher": { "@id": "https://hedge-ops.com/#organization" }
}
]
}
</script>Notice where it says sameAs above? It's exactly what it looks like. You're telling AI, "Hey, these sites vouch for me." In technical terms, these profiles help to disambiguate the entity.
Structured Data Prompt
Here's the prompt you'll use, but before you do that, you'll need to edit it. So read through it and replace all text in brackets [ ] with your unique data (and remove the brackets):
I want to add JSON-LD structured data to every page of my website for
Answer Engine Optimization.
About my business:
- [Company name, one-sentence description, website URL]
- [Founder names and roles]
- [Social URLs you want AI to verify you against (LinkedIn, X, YouTube, etc.)]
- [The page types your site has (home, services, blog, etc.)]
Page types on my site: [examples: home, services, blog posts, etc.]
Generate a single JSON-LD @graph block I can put in the <head> of every
page. Requirements:
- Exactly one <script type="application/ld+json"> per page
- Everything wrapped in "@graph": [...]
- Stable @ids: [https://yoursite.com/#organization,
https://yoursite.com/#person-jane-doe, etc.]
- Entities cross-referenced by @id, never inlined (BlogPosting.author
points to Person's @id; Person and Organization declared once)
- Organization + WebSite on every page
- WebPage on every non-homepage page; BlogPosting on blog posts;
BreadcrumbList on every non-homepage page
Then tell me where to drop it into my [Zola / Astro / Next.js /
WordPress / etc.] site so every page renders it.This will go wherever your site renders the <head> of every page (your layout, theme header, or base template). AI can tell you where that is if you don't know.
Verify: Just paste your URL into validator.schema.org. You can fix anything that's missing or broken (and ask AI to validate your JSON). You can go further and use Google Rich Results Test to see what Google parses. And that's it!
Don't forget to validate! Our validators run on every PR. We have structured-data assertions that check JSON-LD presence, @graph shape, required nodes per page type, and @id cross-reference integrity (no dangling references). The build fails on any violation.
Lever 2: Semantic HTML (writing pages AI can quote)
What if you showed up to the grocery store and there was nothing on the packaging, just a bunch of white boxes, cans, and bottles. You could guess what's in some of them, but you'd probably just ignore a lot of them because it'd be really difficult to determine their contents. Well, a lot of our websites are doing that very thing. So if you want it to be able to quickly scan your website and know about what you offer, then you need to have everything well organized and labeled. I'll show you how to ensure your site is formatted in a way that AI prefers to read.
This is the lowest hanging fruit, most likely, but it makes a big difference.
Why semantic HTML matters for AI
If you're creating a section of text on your website, you could choose to write a div like <div class="post-body">, and it would work just fine. The problem is that AI would not think it was anything significant, just generic content. But if you labeled it instead as an <article>, then now AI pays attention and thinks, "Oh, I need to treat this as standalone, quotable, with known author and date."
The same goes for <header>, <time>, <footer>, etc. If those tags aren't there, the AI has to guess what's what, and that's not always accurate. Labeling everything properly is very important for AI citation previews.
What we changed
I created a ticket that said why semantic HTML matters, and then gave instructions for the agent to audit my entire website and create a list of what needed to be changed, creating a ticket for each change.
Semantic HTML & Accessibility Audit Prompt
Here's the prompt I gave the agent. Remember to replace anything in brackets [ ] with your own information.
I want to audit my website for semantic HTML and accessibility
anti-patterns. AI engines treat properly-labeled HTML as more
quotable than generic <div>s, so this matters for Answer Engine
Optimization.
About my site:
- [Site URL, or paste the template / page HTML]
- [Framework: Zola / Astro / Next.js / WordPress / etc.]
- [Content types: e.g., home, services, blog, docs, pricing]
Audit each content type and recommend changes. Apply these rules:
- Exactly one <h1> per page
- Every <section> has an aria-labelledby pointing at a real heading
on the page
- Replace generic <div>s with semantic equivalents (<article>,
<section>, <aside>, <header>, <footer>, <nav>, <main>, <figure>)
wherever the meaning fits
- Treat repeated content items (blog posts, pricing plans, doc
entries, etc.) as self-contained quotable units — each its own
<article> with appropriate <header> and <footer>
Also flag accessibility anti-patterns:
- Text contrast below WCAG AA
- aria-label values that don't match the visible text
- Animations or transitions that render text invisible at any
point in their duration
- Empty spacer or wrapper elements that could be replaced with
modern CSS layout (gap, margin, padding)
Output as a list of discrete tickets I can work on one at a time.
Each ticket should include: file/template, current markup,
proposed markup, and why it matters.For my website, that list ended up being:
- One H1 per page (enforced in CI).
- Every
<section>hasaria-labelledbypointing at a real heading on the page. - Blog posts wrap in
<article>with<header>(title + byline + date),<figure>for hero image,<footer>for tags/categories. - Docs use
<article>+<aside>with three distinctly labeled<nav>regions. - Pricing plans each become
<article aria-labelledby="plan-{slug}-name">- each plan is its own quotable unit.
Then I had agents work one at a time to implement those changes, and that was it!
Anti-patterns we found and fixed A nice side effect of this audit was that it also found certain other anti-patterns that needed fixing, such as:
- Opacity-tinted text colors (
text-foreground/50) that dropped below WCAG AA contrast in dark mode. aria-labelmismatches with visible text.- CSS animations with
opacity: 0+animation-delayrendering text invisible during the delay window (audit tools read this as low-contrast text). - Empty spacer
<div>s. (Usegapon the parent instead.)
I followed the same pattern with these changes as I did with the semantic HTML. I had the agent create a list of what needed to be changed, tickets with all of the details, and I had agents working on them one at a time.
Lever 3: LLMs files (publishing for AI directly)
What llms.txt is
A proposal to standardise on using an /llms.txt file to provide information to help LLMs use a website at inference time. - llmstxt.org
The proposal is that you would have two files in your website for LLMs to use:
- an
/llms.txtserving as a curated index of pages with title, URL, description, grouped by section (Core, Documentation, Blog, Personas, About) - an
/llms-full.txtwith a concatenated full markdown of every documented page
There was some debate as to the usefulness of these files and if people would start adopting this practice, but when Anthropic, Stripe, Vercel, Perplexity, and other major players began publishing their own llms.txt, a lot of folks (myself included) concluded that it would soon become a well-adopted convention. If not, no big. It's low-hanging fruit.
The level of effort for it is low, so I look at it as a might as well type of task.
How we generate ours
We use Zola for our sites, which I've been pretty happy with. It's a static site generator that uses TOML frontmatter. All of the pages are just markdown files in a content/ folder. So this approach I'm going to tell you about can port to any framework that has metadata on each page. You'd just change it to fit your field names.
I created a post-build script that walks through my content/ folder and emits both files based on the content. You can look at both here:
Two stipulations we put on our files were:
- Inclusion/exclusion via frontmatter (
draft = true,extra.no_llms = true) - never hardcoded paths. - Idempotent (byte-identical across runs), 5 MB hard cap on
llms-full.txt, fail-loud if missing.
Additionally, our site build asserts the llms.txt files exist and stay under the 5 MB cap so that there are no silent regressions.
Making it discoverable
Because llms.txt isn't a universal convention for bot crawlers just yet (some are expecting it to be), we need to tell the bots that the files exist. There are two places they'll be looking for guidance:
robots.txt - This is a file at the root of your website directory that tells crawlers what they can and can't access. If you don't already have one, then now is the time to add it. This is where you can direct the bots to look at your llms.txt and llms-full.txt. You can see mine here: people-work.io/robots.txt
As you can see, we simply reference both files as comments, not directives. There is no LLMs directive that is officially supported just yet, so if you put these instructions as comments, they are ignored by the parser but visible to any human or AI inspecting the file.
<head> - Another way that you can tell the bots where to look is in the <head> of each page. You can tell the crawler reading your HTML, "Hey, there's also a plain text version of this site over here." I implemented this on my base template so that every page on my site advertises the files automatically.
<link rel="alternate" type="text/plain" title="llms.txt" href="/llms.txt" />
<link
rel="alternate"
type="text/plain"
title="llms-full.txt"
href="/llms-full.txt"
/>Lever 4: Off-site presence (building credibility out in the wild)
Okay, we're on to the fun part now! Once you finish with levers 1, 2, and 3, then all of the work you do with Lever 4 will be amplified. Levers 1, 2, and 3 are tactical and Lever 4 is strategic. It's all about getting known for something.
If you don't know someone and you need to make a quick decision about whether or not you can do business with them, what do you do? You ask around. Well, AI does the same thing.
For example: Let's say you're a baker, and you wrote an extensive blog post about making sprouted whole wheat sourdough bread at altitude. Well, AI as well as my baker readers will know that this is a feat. AI needs to know that you know what you're talking about before it can vouch for you. But wait, you're mentioned in King Arthur Baking as one of the foremost experts on using sprouted whole wheat. And, what's this, you appeared in a segment on Good Morning America showing how you sprout whole wheat from home? And just about every sourdough influencer online has linked your article? Wow, you must know what you're talking about.
When you show up in a bunch of different sources, those sources are lending their credibility to you. The bigger and more credible the better. Showing up in many sources matters more than ranking #1 in any single one.
According to Backlinko's LLM sources study, LLMs used to source heavily from Reddit, but YouTube is now the fastest-rising citation source. This trend is something you'll want to stay attuned to.
Long-tail questions
With search, we have historically averaged about 6 words per search. AI chat questions, however, average about 25 words. That means we're getting more specific and granular with what we're searching.
The encouraging thing for early stage companies is that you don't need a ton of domain authority to be cite-worthy. You just need to answer the specific questions that customers are asking.
So here's your first homework assignment:
Identify a long-tail question that you can own. What are specific questions that no one else has answered well that you can nail?
While authenticity matters above all else when creating content, there are some types of posts that work well for AI cite-worthiness:
- Comparison posts ("best X for Y") are the highest-value single piece.
- Question-titled blog posts ("How do new engineering managers build relationships with stakeholders?") - These are your long-tail questions.
- YouTube - Companion videos to your top posts
Directory profiles (one-time, ~1 hour each)
There are also a lot of directories online in which you can create a profile where people can learn about your app. These include but are not limited to:
Determining which directories apply to you can be of benefit. Every profile is a potential citation source. Keep in mind that you may have to have a fully baked product or service before being included in certain profiles.
Engagement (~30 min/week per channel)
For ongoing mentions online throughout the week, think about spending about 30 minutes a week per channel on answering questions, commenting, and other forms of engagement on social platforms.
- On Reddit, participate in your category's subreddits. Say who you are and give useful answers.
- On LinkedIn, comment on industry posts in your space. This not only gives you visibility, but the LinkedIn algorithm also rewards this type of engagement.
Listicle outreach (~1–2 hours/month)
Just like with certain directory profiles, in order to be included on listicle articles, you will need to have a fully baked solution. But if you are ready for this, then you can email authors of "best X" articles to request to be included in their articles. Be specific about why you fit and provide confident examples.
Doing all of these exercises will not only help your reach, but also help you to simplify your messaging, honing it into a clear and memorable offering.
What we can measure (and what "passing" tells us)
If you want to check what "grade" you're getting with AEO and SEO right now, then go to both of these sites to get audited for free in less than 5 minutes total:
- Lighthouse - Measures the following:
- Performance
- Accessibility
- Best practices
- SEO
- HubSpot's AEO tracker - Measures the following across ChatGPT, Perplexity, and Gemini:
- Brand Recognition
- Market Score
- Presence Quality
- Brand Sentiment
- Share of Voice
To give you a sense of what "passing" looks like, here's where we landed after working through Levers 1–3:
Lighthouse (Desktop)
| Site | Performance | Accessibility | Best Practices | SEO |
|---|---|---|---|---|
| Hedge-Ops | 100% | 94% | 100% | 100% |
| People Work | 92% | 96% | 77% | 100% |
These are pretty good scores, if I do say so. I do want to look into that 77, but Lighthouse is mostly telling me that the site is technically healthy: fast enough, accessible enough, using search-friendly basics, and not hiding important content from crawlers. That matters for AEO, but it is not the same thing as proving an AI engine will cite or recommend us.
Hubspot AEO Tracker
Hedge-Ops
| Engine | Brand Recognition | Market Score | Presence Quality | Brand Sentiment | Share of Voice |
|---|---|---|---|---|---|
| OpenAI | 2/20 | 6/10 | 5/20 | 20/40 | 0/10 |
| Perplexity | 4/20 | 3/10 | 6/20 | 17/40 | 1/10 |
| Gemini | 2/20 | 6/10 | 5/20 | 27/40 | 0/10 |
People Work
| Engine | Brand Recognition | Market Score | Presence Quality | Brand Sentiment | Share of Voice |
|---|---|---|---|---|---|
| OpenAI | 2/20 | 3/10 | 5/20 | 20/40 | 1/10 |
| Perplexity | 2/20 | 3/10 | 5/20 | 22/40 | 10/10 |
| Gemini | 2/20 | 3/10 | 5/20 | 31/40 | 1/10 |
These HubSpot numbers tell me a completely different story, don't they?
Something worth noting: Perplexity scored us at 10/10 Share of Voice while ChatGPT and Gemini scored us 1/10. The reason is that Perplexity does live web retrieval, so perhaps the work I've done as described in this post is actually surfacing in that score. I can't say for sure, but each engine has a different way of doing retrieval and citation, so one engine's score is not enough to prove what moved. Structured data and llms.txt may help with discoverability and parsing, but citation-based reach is the longer game.
These checks do not prove that AI is recommending you, but they do give you evidence that your pages are easier for crawlers, search engines, validators, and AI-powered retrieval systems to parse. If you want to know if you're actually getting recommended by AI, you'd still need to look at website analytics, referral traffic, customer surveys, and direct prompt testing over time. Running these tools monthly and treating them as diagnostics is still a good practice for baseline system health, though.
What we're still working on: the naming problem
I asked again. I told you in the beginning of this post that a year ago I tried to get AI to recommend my product. More recently, I asked again, and it still didn't recommend my product. I worried that I was failing at AEO, after all that work. But when I redid the audits I realized that it wasn't a problem with my site; it was more of a positioning problem. You see, these exercises give you more data than just reach. They help you to refine your own clarity about what's broken.
Ask AI why. The most important question in my conversation with AI was, "Why didn't you suggest People Work?" It said something to the effect of, "Oh you know, actually, People Work would be perfect for these reasons..." So that told me that the work on the site and in my socials was solid. Once it knew about me, it had a very clear picture.
Why it didn't suggest me. And it went on to give me all of the reasons that it didn't think to suggest us, like how it confused our name with another product called PeopleWorks which is a traditional HR software, and that we're still new and don't have enough other people talking about us.
What now? That basically told me that the two main things I need to be working on are:
- Getting people to vouch for us in the form of reviews, listicles, mentions, etc. (positioning has to come first for this to be possible)
- Assessing whether we need to change the app name
I am not deterred, though. AEO is an ongoing practice. And if you listen, you'll get valuable insights back.
Where to go from here
If you do nothing else, paste your URL into validator.schema.org today and see what you're missing.
The most important thing to learn from this whole post is that having good AEO really is an ongoing practice. Sure, the first couple of things can be done by an agent and don't take too long, but all of the rest of it is a practice in clarifying your messaging and getting other people to understand what you're all about. That's when you start to see the compounding effects of all of your hard work, and hopefully you will start to see that positively affecting your company's success, as well.
If you'd rather not navigate that on your own, get in touch. I'm happy to set up a call to see if I can help. (You can also use that link to simply ask clarifying questions about this post.)
I sincerely hope this was helpful for you. Good luck on your AEO journey!
Reference List
Here is a list of all of the sites referenced so that you can have them in one place:
| Tools to Audit Your Site |
|---|
| Google Rich Results Test |
| validator.schema.org |
| Lighthouse |
| HubSpot's AEO tracker |
| Directory Profiles |
|---|
| G2 |
| Capterra |
| AlternativeTo |
| Product Hunt |
| Further Reading |
|---|
| Ethan Smith's AEO playbook |
| Backlinko's LLM sources study |
| llmstxt.org |